I have always been curious about music production but have never had any musical inclinations or skills. Using AI, I was able to learn about music production through the lens of technology. sply85 is a machine learning based AI using neural networks that helps to generate music on its own. The AI digests popular songs and then uses open-source beats, lyrics, sounds to produce music without infringing on copyrights. Check it out here.
Inspired by the biological neural networks in the human brain, artificial neural networks (ANN) build networks of connections to transmit signals and process information. In the brain, neurons connect via synapses and can send signals to one another. These connections strengthen or weaken over time and new connections can grow, a phenomenon called neuroplasticity.
Just as a brain can grow and reorganize over time, artificial neural networks replicate this behavior in a digital environment. Each neuron in an ANN takes numerical inputs from all of its connections or edges. Inside the neuron, a nonlinear function takes those signals as inputs and computes a new value. That value can then be passed on to other neurons in the network where the process repeats. The strength of the signal that is passed to new neurons is affected by the weight of the connection. Just as the human brain strengthens and weakens synapses as we learn, the ANN adjusts these weights to strengthen or weaken connections between neurons.
HOW DO YOU TRAIN AN ALGORITHM?
Artificial neural networks are just like human brains when it comes to learning too. As we learn, certain connections become reinforced making it easier for us to arrive at the correct answer faster. Teaching a toddler to name animals requires a lot of repetition and correction. Neural networks need the same attention.
FROM DETECTING CATS TO MAKING HITS
A simple example model for training a neural network often involves cat pictures. With a database of pictures that are known to have cats, a neural network can take that data and start to learn what makes a cat special. Instead of telling the algorithm that a cat has whiskers and paws and a tail, showing it a large enough dataset allows the proper connections to strengthen for the algorithm. The model learns these unique characteristics over time and can then detect whether or not a new picture has a cat in it. Unfortunately, making beautiful music is a bit more difficult than detecting cat photos.
GETTING THE DATASET JUST RIGHT
To train our algorithm, we first had to get a proper dataset together to train the neural network. Certain bits of metadata had to be identified so that the algorithm would know what it was processing.
Key features of songs were documented like:
The beats per minute throughout the song
The presence of various pitches
Frequencies
Sounds
Classifying parts of the song
In addition to highlighting these aspects for the algorithm, we also classified the vocals and uploaded the lyrics. Songs were broken into segments for the algorithm to process including intro, outro, chorus, pre-chorus, verse, bridge, and hook. Libraries of copyright free voice tracks were classified and uploaded to give the algorithm a wide sampling of different vocals.
TIME TO HIT THE GYM
With a robust and cleanly classified dataset, it was time for the algorithm to start training. The method used for training an algorithm has as big an impact as the dataset. While many different approaches were tested, two methods showed the most promise.
Librosa Approach
With librosa, audio inputs were converted to Mel-Frequency Cepstral Coefficients (MFCC) and then used to train the model. Essentially what happens is these coefficients are calculated based on frequency bands and are spaced logarithmically according to the Mel scale, a perceptual scale of pitches that listeners perceive to be equally spaced from one another.
A Multi-Pack Approach
Using a multi-pack approach, we combined RNN, multi-instrument RNN, MelodyCNNs, HarmonyCNNs, Variational Autoencoders (VAEs), GANs, and Transformers to train our model. With this dream team of methods, we were able to produce several outputs for each part of the song that could be used to train our model.
MAKING SOME MUSIC
With the algorithm learning from some of the greatest hits, it was time for it to start making some masterpieces of its own. The functional result was a text-to-music style AI generator. After the model produces a song, we take the raw files and help to smooth the transitions. Some portions of the song have to be linked up where they make more sense and the songs are then remastered. This portion of the process has to be handled very delicately out of respect for what the algorithm has created. Like an art restorer touching up a masterpiece, the goal is to smooth the edges without changing the underlying art.
THE CHALLENGES
While writing songs is hard, teaching a computer to write them is even harder. Building this algorithm was no exception. Some of the biggest challenges were making songs more coherent and avoiding direct copying.
As the AI generated different portions of a song, bringing those pieces together into one coherent song was not always easy. The algorithm would generate songs in a very clunky way that did not have a polished feel.
They say creativity is just undetected plagiarism. The early versions of our neural network would probably agree. We had to tone down any actual direct copying of sounds to prevent any issues with copyright laws. While doing this, we also had to encourage the model to use similar chords for small stretches.
AI: THE FUTURE OF MUSIC
Being able to distill music down into its key elements and learn from them gives AI a great advantage over humans. As the algorithms are refined and the datasets grow, the outputs will only get better. The future of music is AI generated and the future is closer than you think.
REFERENCES
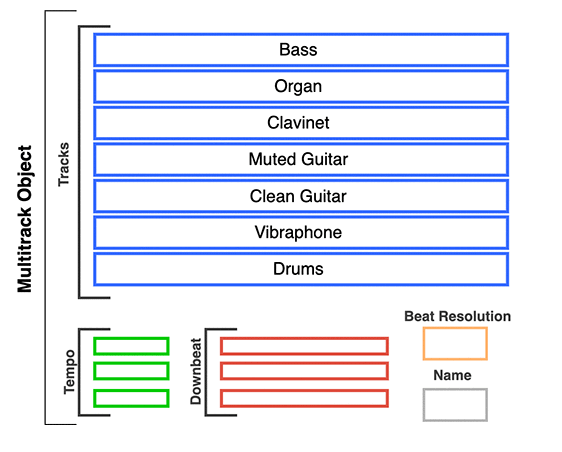
Dong, Hao-Wen, et al. “Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
Ji, Shulei, et al. A Comprehensive Survey on Deep Music Generation: Multi-Level Representations, Algorithms, Evaluations, and Future Directions. https://arxiv.org/pdf/2011.06801v1.pdf.





SocialMEDIA
sply85 is music generated from a machine learning based AI using neural networks that helps to generate music on its own.